Voorspel de toekomst met Qlik AutoML

De heilige graal voor ieder bedrijf dat met data aan de slag gaat is het voorspellen van de toekomst en daarop kunnen acteren. Het is de hoogste trede van de Gartner ladder voor volwassenheid op het gebied van data-analyse. Tot voor kort was Qlik vooral geschikt voor het ondersteunen van de eerste twee trappen van de ladder. Dat was tot Qlik in september van dit jaar AutoML beschikbaar maakte binnen het Cloud platform. Met AutoML zien we wederom een eerdere aqcuisitie, die van Big Squid, terugkomen als geïntegreerde functionaliteit. In dit blog legt senior consultant Lennaert je uit hoe Qlik AutoML precies werkt.
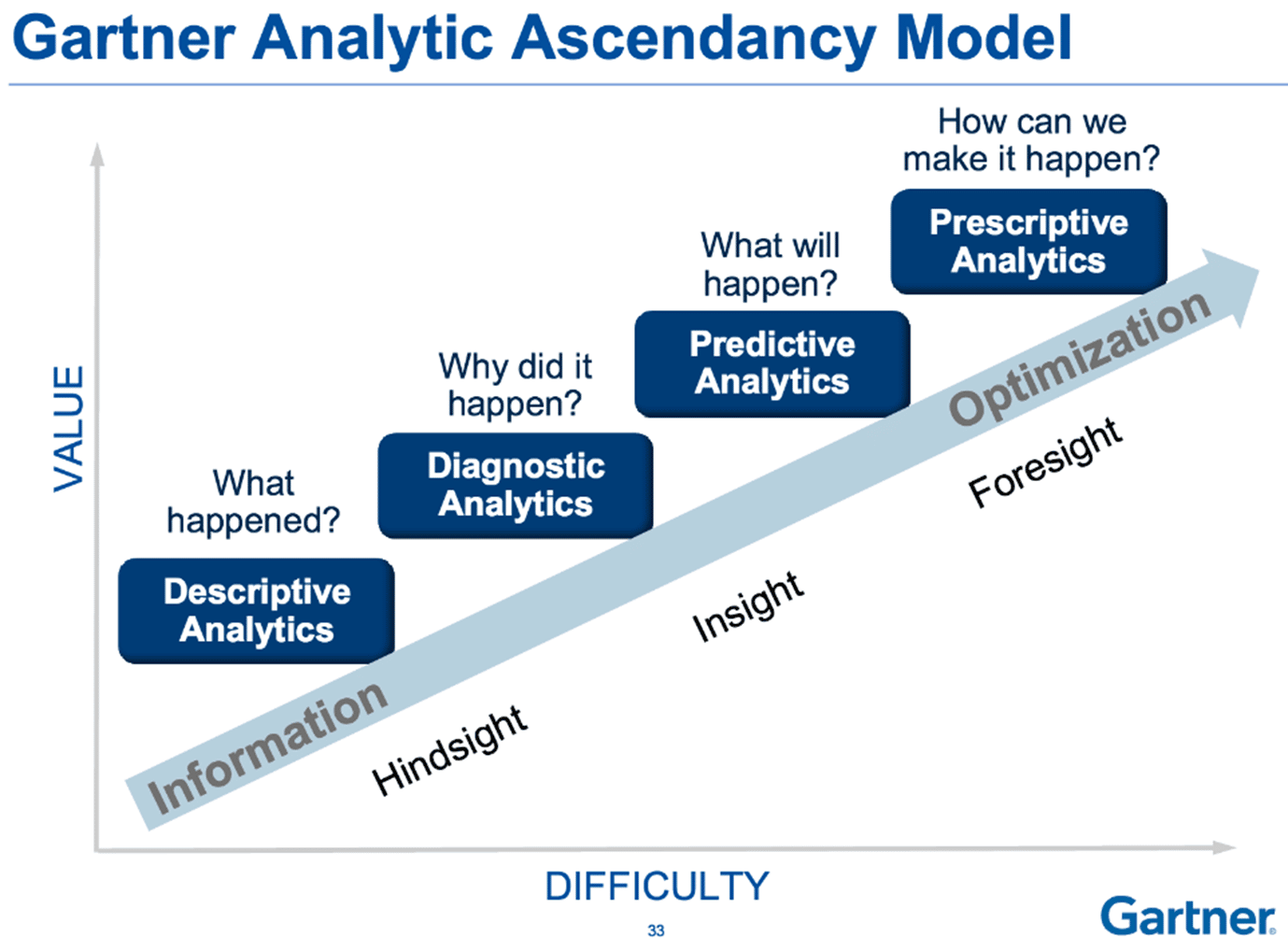
Gartner ladder
Zoals je in de Gartner ladder voor volwassenheid op het gebied van data-analyse hieronder ziet zijn er 4 niveau’s van volwassenheid. De eerste stap is de beschrijvende analyses die antwoord geven op de vraag wat er gebeurd is. Denk dan bijvoorbeeld aan een eenvoudige jaarafrekening. Je ziet daarop precies hoe veel geld er is binnengekomen en hoeveel er is uitgegeven. Ben je een stapje verder, dan wil je ook weten waarom de kosten bijvoorbeeld hoger zijn dit jaar. Je gaat op zoek naar verbanden en verklaringen. Bij voorspellen gaat het dan om, op basis van historische gegevens, een voorspelling te doen over wat er gaat gebeuren. Denk dan bijvoorbeeld aan vragen als: “Gaat deze klant zijn abonnement opzeggen?”, “Wanneer gaat deze machine stuk en wat gaat er dan precies stuk?” of “hoeveel extra omzet verwacht ik als ik een extra kortingsactie start?”. Vervolgens is de laatste stap om dan ook daadwerkelijk aan de hand van acties te dicteren wat er gaat gebeuren, dus bijvoorbeeld: “als we deze klant nu 10% korting geven op zijn maandbedrag zal hij zijn abonnement waarschijnlijk niet op gaan zeggen”.
Qlik AutoML
Met AutoML kun je ook de stappen naar voorspellen en voorschrijven maken. AutoML staat dan ook voor “Automated Machine Learning”. Wat normaal gesproken de stappen naar voorspellend en voorschrijvend zo lastig maken is dat je daar over het algemeen zeer specialistische kennis voor nodig hebt, die maar lastig te verkrijgen is in de markt. Niet voor niets staat het beroep van Machine Learning Engineer op de 4e plek in de top 25 snelst groeiende functietitels van 2022 op LinkedIn. Het is dus niet altijd even makkelijk om een ML-expert in dienst te krijgen en als hij of zij dan eenmaal in dienst is zal hij het al snel heel druk hebben om aan alle vraag te voldoen.
Machine Learning
Qlik AutoML maakt het een stuk eenvoudiger om met Machine Learning aan de slag te gaan. Hoe het precies werkt leggen we verder op in dit blog uit, maar het basisconcept is dat je AutoML een dataset geeft om op te trainen en vertelt welke waarde je wil voorspellen. AutoML zal vervolgens op basis van het soort voorspelling een aantal passende algoritmen trainen en optimaliseren en vertelt je welke het beste werkt. Vervolgens kun je dat voorspelmodel toepassen op een nieuwe dataset die je vervolgens gelijk in Qlik kan visualiseren. Op deze manier kan niet alleen een ML expert in kortere tijd veel meer werk verzetten, maar wordt het ook toegankelijker voor data analisten met minder expertise kennis op het gebied van ML.
Starten met AutoML
Het startpunt voor AutoML is data in de catalog van je Qlik Cloud omgeving. Het maakt daarbij niet uit of het een QVD is of bijvoorbeeld een Excel of CSV bestand. Het belangrijkste is dat dit databestand in ieder geval een “Target” en een aantal potentiële factoren (“Features”) bevat. De “Target” is de kolom die je wil voorspellen, dus bijvoorbeeld in ons geval de kolom “Churned”, die met “yes” of “no” aangeeft of de specifieke klant zijn abonnement uiteindelijk heeft opgezegd. Potentiële factoren zijn in ons geval bijvoorbeeld “PlanType”, het soort abonnement, of “ CustomerTenure”, het aantal dagen dat een klant al abonnee is. Om te beginnen met het experiment klikken we in Qlik Cloud op “Add new” en kiezen we voor “New ML experiment”.
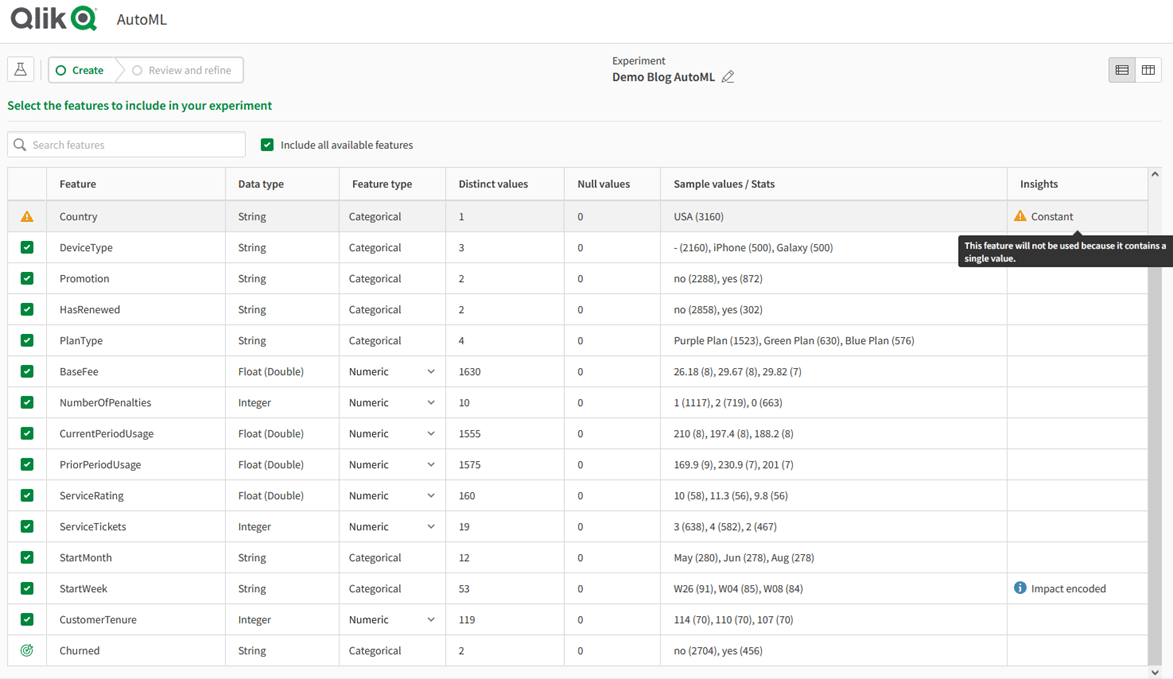
Zodra we daarop hebben geklikt moeten we ons experiment een naam en omschrijving geven en kiezen we de Space waar hij zal worden opgeslagen. Als we dat gedaan hebben vraagt Qlik ons de bron dataset aan te wijzen waar onze historische data met daarin de Target en Features. Vervolgens zal AutoML je vragen welke kolom de “Target” bevat, oftewel, welke waarde je wil voorspellen. Zodra je deze aanklikt worden automatisch alle andere velden als potentiële features aangemerkt. Door middel van vinkjes zetten kan de sommige kolommen uitsluiten als je van tevoren al weet dat ze niet gaan helpen. Daarnaast zal AutoML ook van een aantal velden een waarschuwing geven, zoals in ons geval bij de kolom “Country”. Deze kolom bevat namelijk maar 1 waarde en zal dus nooit nuttig zijn om een voorspelling op te baseren. AutoML sluit deze waarde dan ook zelf al uit en toont door middel van een waarschuwingsicoon de reden voor uitsluiting. Tot slot kun je in de kolom “Data Type” nog aangeven wat het juiste type is. Dit is voornamelijk relevant voor numerieke waarden. Dat zit zo: een getal heeft een inherente volgorde, 3 is kleiner dan 8. Die volgorordelijkheid kan van belang zijn bij het voorspellen. Een hogere prijs of boete zal waarschijnlijk bijdragen aan een hogere kans op churn. Soms is een getal echter enkel een categorie en maakt de onderlinge volgorde niet per sé uit. Denk bijvoorbeeld aan een fabriekshal nummer. De hoogte van het nummer van de hal zal geen voorspellende waarde met zich meedragen.
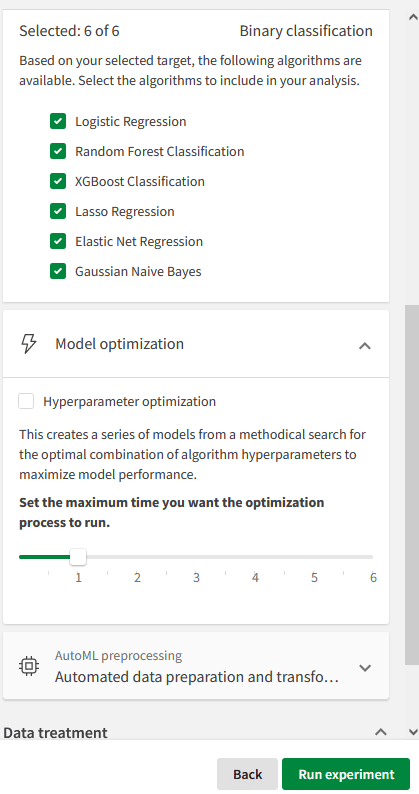
Als je eenmaal de “Target” en “Features” hebt bepaald en de juiste categorisering hebt aangebracht zal AutoML zelf een voorstel doen voor een aantal algoritmen die goed zouden kunnen werken om de voorspelling te maken. Je kunt zelf aangeven of je deze allemaal wil gaan trainen of dat je een specifiek algoritme wil uitsluiten. Daarnaast kun je aangeven of er gebruik gemaakt moet worden van “Hyperparameter optimization”. Het gaat voor dit blog te ver om in te gaan op wat die optimalisatie in houdt, maar in het kort zal AutoML met “Hyperparameter optimization” de interne parameters van de algoritmen proberen zo goed mogelijk af te stemmen op jouw specifieke case. Dat kan in sommige gevallen wel behoorlijk lang duren, vandaar dat je de mogelijkheid hebt om een maximumtijd in te stellen die de optimalisatie mag duren. Als je deze bijvoorbeeld instelt op 1 uur, dan zal AutoML na dat ene uur stoppen met de optimalisatie (als hij nog niet klaar was) en het tot dan toe beste resultaat presenteren.
Als deze instellingen naar wens staan druk je op de knop “Run experiment”. AutoML gaat vanaf dat moment aan de slag om alle geselecteerde modellen te trainen op jouw dataset. Afhankelijk van het soort variabele die je probeert te voorspellen krijg je net een iets ander resultaat te zien. In ons geval werken we met een binaire classificatie (een klant zegt wel of niet zijn abonnement op). Andere soorten problemen zijn meervoudige classificaties en numerieke voorspellingen.
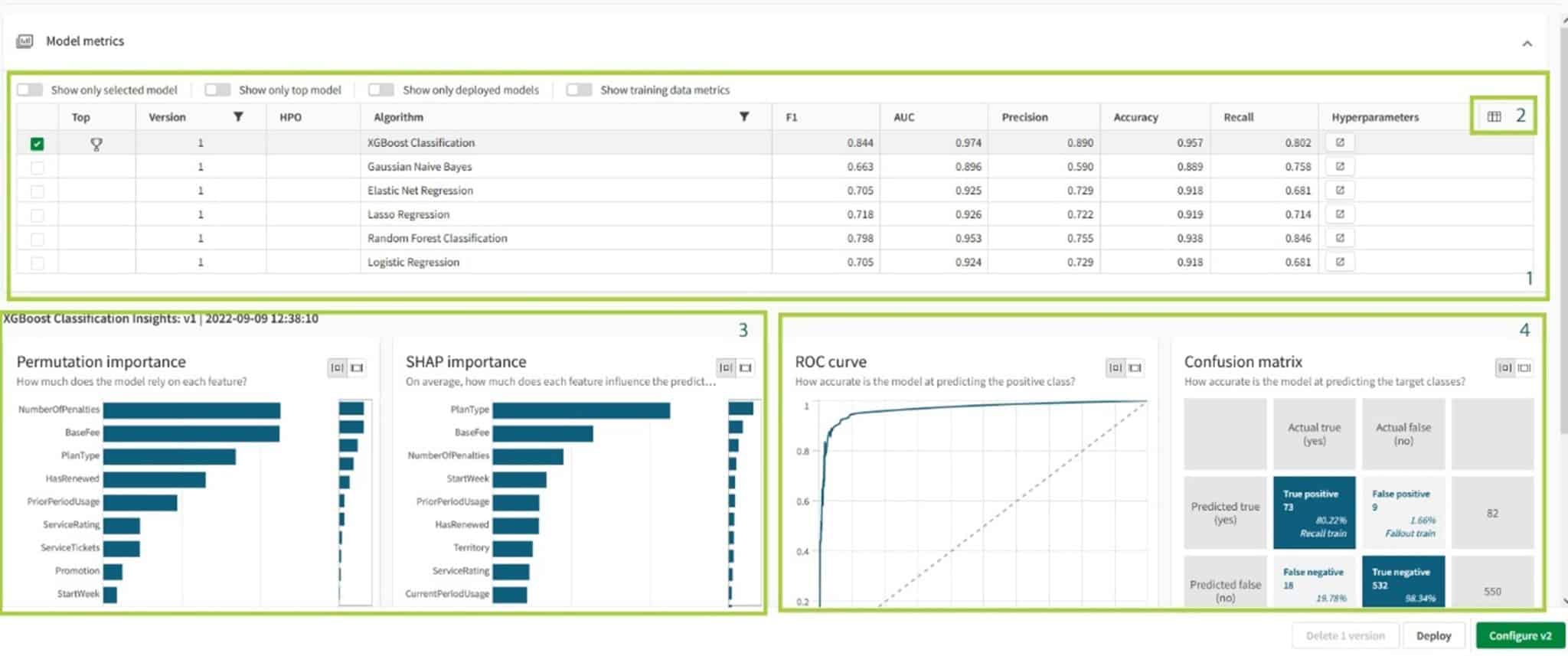
Zoals je hierboven kunt zien is in ons voorbeeld “XGBoost Classification” als beste uit de bus gekomen. Standaard presenteert Qlik een tabel (1) met een aantal veelgebruikte meetwaarden om een dergelijk algoritme op te beoordelen. In deze standaard situatie zie je meetwaarden als “Precision”, “Accuracy” en “Recall”, maar onder de knop rechtsboven (2) in de tabel kun je nog veel meer meetwaarden vinden. Voor dit blog gaat het te ver om elk van de mogelijke meetwaarden uit te leggen, maar voor de geoefende ML expert beschrijven deze meetwaarden hoe goed het het algorimte is en op welke manier het af en toe toch mis kan gaan.
Gelukkig maakt AutoML de belangrijkste conclusies op basis van deze waarden ook visueel inzichtelijk. De grafieken links onder laten zien welke features belangrijk zijn voor het model en in welke mate ze de target beïnvloeden. De grafieken rechts onder geven een indruk hoe nauwkeurig het model is in het voorspellen van de uitkomst en welk soorten fout het meest gemaakt worden (false positive of false negative).
Vanaf dit punt kun je 2 kanten op. Als je nog niet tevreden bent met de uitkomst kun je een tweede configuratie uitproberen, door bijvoorbeeld een bepaalde Feature toch wel of juist niet mee te nemen of door de winnaar nogmaals te trainen maar dan met Hyperparameter optimalisatie wel aan. Doe je dit, dan zal opnieuw een set algoritmen getraind worden en komen de resultaten er bij in de tabel. Je kunt dan dus ook gelijk zien of de aanpassingen een positief of negatief effect hebben op het resultaat.
Als je eenmaal tevreden bent over het resultaat kun je deze selecteren door middel van het vinkje en vervolgens kiezen voor “deploy”. Ook nu moet je de deployment weer een naam en beschrijving geven en een space kiezen waar de deployment in terecht komt. Eenmaal opgeslagen kun je deze deployment openen. Door op “Create prediction” te klikken kun je vervolgens een nieuwe dataset kiezen waarop je de voorspelling wil toepassen. In ons geval dus een dataset met huidige klanten waarvan we de churn willen voorspellen. De output van de prediction zal worden opgeslagen in een nieuwe dataset, dus ook daar moeten we een naam voor invoeren. Naast de voorspellingen kunnen we ook een aantal andere interessante QVDs laten wegschrijven, zoals de SHAP waarden. Ook moeten we aangeven wat de sleutel van deze QVDs zal zijn naar onze oorspronkelijke dataset. In het ideale geval is dat een ID kolom die al aanwezig is, maar als dat niet zo is kun je AutoML ook een ID laten genereren. Als we tot slot op de knop “Predict” klikken gaat Qlik aan de slag en maakt hij de nieuwe QVDs aan.
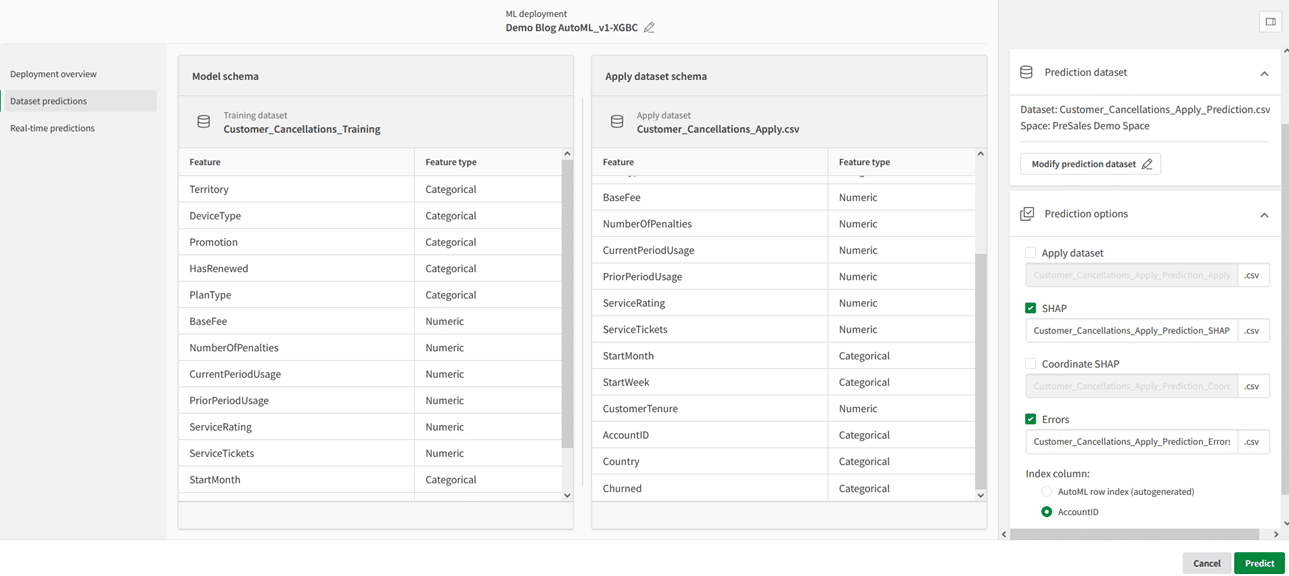
Zoals gezegd is het resultaat een nieuwe dataset met daarin de voorspelling. In ons geval levert dat ons een tabel op met 4 kolommen: het ID als sleutelveld, de kolom “Churned_predicted”, waarin de voorspelde waarde staat, en de kolommen “Churned_no” en “Churned_yes” die per variant aangeven wat de voorspelde kans op die waarde is. We kunnen dus ook al in actie komen als de kans op Churn boven een bepaald percentage uitkomt. Deze dataset kunnen we vervolgens inladen in een dashboard om te visualiseren.
Qlik AutoML in actie zien?
Zoals je hierboven hebt gezien is het relatief eenvoudig om vanuit een dataset tot een voorspelling te komen met AutoML, maar is er ook zeker veel ruimte voor verdieping voor de echte ML experts. De feature is op dit moment voor alle Qlik Cloud Enterprise klanten gratis beschikbaar, maar kent daarbij wel een aantal beperkingen. Zo ben je in de gratis variant beperkt in de grootte van de dataset die je kan gebruiken om het model te trainen. Het aantal rijen vermenigvuldigd met het aantal kolommen mag daarbij niet boven de 100.000 komen. Ook mag je maar een beperkt aantal deployments uitvoeren met de gratis variant. Ben je geïnteresseerd en wil je AutoML live in actie zien? Neem dan contact op voor een demo via onderstaand formulier.

Geschreven door Lennaert van den Brink
Senior Consultant






