Aan de slag met AutoML: model selectie

De toekomst voorspellen, wie wil dat nou niet? Met Qlik AutoML kun je eenvoudig voorspelmodellen creëren op basis van jouw data. Zoals de naam van de functionaliteit verraadt, automatiseert Qlik AutoML een groot deel van dit proces voor je. Desondanks heb je als gebruiker nog steeds wel een hoop invloed op de effectiviteit van het voorspelmodel. In deel 2 van deze blogserie leggen we je uit wat je kan doen om jouw voorspelmodellen met AutoML nog beter te maken en hoe je het resultaat kunt integreren in je bestaande Qlik dashboards.
Wat is model selectie?
In het eerste deel van de blogserie hebben we uitgelegd hoe je “feature engineering” kunt toepassen om de trainingsdata voor jouw model te optimaliseren. De volgende stap is dat we daadwerkelijk modellen laten trainen.
De eerste keuze maak je al in de eerste stap van de configuratie van een experiment. Afhankelijk van het soort voorspelmodel dat je wil maken selecteert AutoML een aantal mogelijke voorspelmethodieken (algoritmen) die gebruikt kunnen worden voor het voorspelmodel. Er zijn 3 typen voorspelmodellen die Qlik kan toepassen:
- Binaire classificatie: Het veld wat je wil voorspellen kent 2 mogelijke uitkomsten, bijvoorbeeld Ja of nee, 1 of 0, waar of niet waar.
- Meervoudige classificatie: Het veld dat je wil voorspellen kent meer dan 2 mogelijke uitkomsten, maar het aantal opties is beperkt. Bijvoorbeeld als je wil voorspellen welke kleur auto iemand rijdt, de opties zijn blauw, wit, rood, groen, grijs.
- Regresie: Het veld wat je wil voorspellen is een numerieke waarde. Bijvoorbeeld als je wil voorspellen hoe veel bloemen er gekocht gaan worden in een bepaalde maand.
Afhankelijk van het type voorspelmodel zijn er dus verschillende opties van algoritmes die gebruikt kunnen worden. Je kan ervoor kiezen om alle algoritmes mee te nemen in het experiment, maar als je van tevoren al een voorkeur hebt zou je specifieke modellen kunnen uitsluiten.
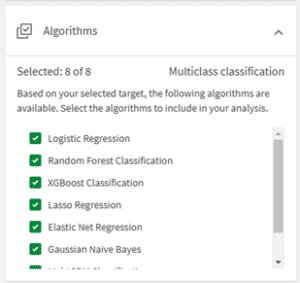
Wanneer je de algoritmes hebt gekozen en hebt aangegeven welke features gebruikt gaan worden voor het trainen van de modellen, kan AutoML aan de slag. Voor elk model wordt een versie getraind. Maar hoe kies je welk model je uiteindelijk gaat gebruiken? In dit blog leggen we uit welke keuzes je daarin kunt maken.
Het scoringssysteem
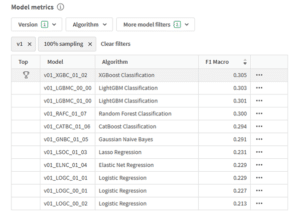
Zodra AutoML klaar is met trainen krijg je een resultaattabel in beeld. In die tabel staat altijd 1 model aangemerkt als winnaar. Afhankelijk van het type voorspelmodel wordt er een verschillende meetwaarde gebruikt om deze winnaar te bepalen.
Voor een binaire classificatie wordt gebruik gemaakt van de “F1” score. De F1 is een samengestelde score op basis van de meetwaarden “Precision” en “Recall”. Beide scores vertellen iets over hoe nauwkeurig het model is. Om dit goed uit te leggen moeten we eerst kijken naar de zogeheten “Confusion matrix”. Stel we proberen te voorspellen of een uitkomst 0 of 1 wordt. Er zijn dan 4 mogelijke uitkomsten: we voorspellen 1 en het wordt 1 (“True positive”), we voorspellen 1 maar het wordt 0 (“False positive”), we voorspellen 0 en het wordt 0 (“True negative”) of we voorspellen 0 en het wordt 1 (“False negative”). Door de verschillende uitkomsten in een matrix te zetten kan je visualiseren hoe goed een model in voorspellen is.
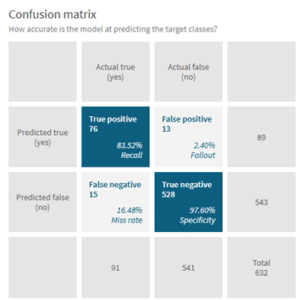
De confusion matrix is een belangrijk gegeven bij het selecteren van het juiste model. In veel gevallen wil je gewoon zo goed mogelijk voorspellen, maar als je bijvoorbeeld in het kader van preventief onderhoud een model maken waarmee we willen voorspellen of een machine stuk gaat heb je liever een false positive dan een false negative. Bij een false positive pleeg je wat extra onderhoud en blijft de machine draaien, bij een false negative gaat de machine toch stuk, met alle gevolgen van dien.
De meetwaarde precision wordt uitgerekend door het aantal true positive te delen door het totaal aantal voorspelde positieve gevallen. Anders verwoord geeft deze meetwaarde aan “als we 1 voorspellen, in hoe veel % van de gevallen is het dan ook echt 1”. Andersom reken je de meetwaarde recall uit door het aantal true positive te delen door de som van true positive en false negative, oftewel “als het in werkelijkheid 1 is, in welk % van de gevallen voorspellen we dan ook 1”.
De F1 score reken je uit door de som:
![]()
Anders gezegd geeft de F1 score aan hoe vaak het juiste antwoord wordt voorspeld.
Nu zou je je af kunnen vragen: waarom delen we niet gewoon het aantal juist voorspelde waarden door het totaal aantal voorspellingen? Dit is de zogeheten “Accuracy”. Hoewel accuracy in veel gevallen sterk overeen zal komen met de F1 score kent dit getal een belangrijk nadeel. Stel, ik zou een voorspelmodel willen maken dat voorspelt of een Eredivisie speler de selectie van het Nederlands elftal gaat halen. De meeste Eredivisie spelers halen het elftal niet, dus mijn voorspel model heeft een hele hoge accuracy als het voor alle spelers voorspelt dat ze het niet gaan halen. Het is dan echter niet een heel nuttig model voor mijn doel. Of je het beste accuracy of F1 kunt gebruiken hangt dus af van 2 factoren:
- Als het geen verschil maakt of je een false negative of een false positive voorspelt en jouw dataset gebalanceerd is (er zijn ongeveer evenveel positives als negatives), gebruik dan de accuracy.
- Als er een onbalans zit in de dataset, of als false negatives zwaarder wegen dan false positives, gebruik dan de F1 score.
Omdat de meeste scenario’s in de echte wereld te maken hebben met ongebalanceerde datasets, is de standaard meetwaarde die Qlik gebruikt de F1.
Scores voor Meervoudige classificatie
In bovenstaande uitleg hebben we vooral gekeken naar het scoringssysteem voor binaire classificatie. Bij meervoudige classificatie gebruiken we dezelfde methodieken, maar moeten we die opschalen naar het grotere aantal labels om de F1 te bepalen. Voor het bepalen van de recall en precision hebben we 3 aantallen nodig: het aantal true positives, het aantal positives en het aantal false negatives. Stel we hebben een classificatie probleem met 3 labels, A, B en C. Onze confusion matrix zou er dan als volgt uit kunnen zien:
| Daadwerkelijk A | Daadwerkelijk B | Daadwerkelijk C | |
| Voorspeld A | 2 | 1 | 0 |
| Voorspeld B | 0 | 1 | 0 |
| Voorspeld C | 1 | 2 | 3 |
Het aantal True positive voor label A is dan nog steeds 2, het aantal keer dat we A correct voorspeld hebben. Het aantal totaal aantal positives voor label A is 3, we hebben in totaal 3x A voorspeld. Het aantal false negative voor label A is 1, want we hebben 1 keer C voorspeld terwijl het A was. Hiermee kunnen we dus een F1 score uitrekenen voor elk label:
| True Positives | Total Postives | False Negatives | F1 | |
| A | 2 | 3 | 1 | 0.67 |
| B | 1 | 4 | 0 | 0.40 |
| C | 3 | 3 | 3 | 0.67 |
Om iets te kunnen zeggen over het voorspelmodel moeten we een manier vinden om de F1 per label bij elkaar te voegen voor alle labels, zodat het iets zegt over het gehele model. Daar heeft AutoML 3 verschillende methodes voor:
- F1 Macro: Tel alle F1 scores bij elkaar op en deel deze door het aantal labels.
- F1 Micro: Tel alle true positives bij elkaar op, doe hetzelfde voor de total positives en false negatives. Gebruik de totalen om de F1 uit te rekenen met de formule :
![]()
- F1 Weighted: Vermenigvuldig elke F1 score per label met het aantal daadwerkelijke waarnemeningen voor dat label. Deel het geheel door het totaal aantal waarnemingen.
Ook hier hangt het weer af van wat je belangrijk vindt voor jouw voorspelmodel. Is elk label even belangrijk, dan kies je de F1 Macro. Wil je vooral de veelvoorkomende labels goed voorspellen kies je de F1 Micro. De F1 weighted is de middenweg en is vooral effectief bij grotere onbalans tussen de verschillende labels.
Scores voor regressie
Voor een regressie model moeten we met een heel andere scoringsmethodiek werken. We proberen namelijk geen discrete klassen te voorspellen, maar zijn een getal aan het raden. Stel je voor dat we een getal tussen de 0 en 100 moeten raden. De kans dat we het exact goed hebben is heel klein (1% als we ons tot hele getallen beperken), maar het is nogal een verschil of we er dicht in de buurt zitten of juist ver vanaf.
Om de resultaten van een regressie model te scoren gebruikt Qlik standaard de R2 (“R-squared”) als score. De R2 is een score van -1 tot 1 en geeft aan in hoeverre het model de verandering in output (de waarde die we willen voorspellen) kan verklaren aan de hand van de verschillende input waarden.
Om uit te leggen hoe we de R2 kunnen berekenen gaan we 5x een getal tussen 0 en 100 raden. Per keer dat we een getal raden nemen we het verschil tussen het daadwerkelijke getal en het getal dat we hebben geraden. Dit noemen we het residu. Daarnaast nemen we het verschil tussen de daadwerkelijke waarde en het gemiddelde van alle daadwerkelijke waarden, de afwijking.
| Daadwerkelijk getal | Voorspeld getal | Residu | Afwijzing |
| 55 | 91 | -36 | 11 |
| 12 | 19 | -7 | -32> |
| 98 | 35 | 63 | 54 |
| 38 | 50 | -12 | -6 |
| 17 | 27 | -10 | -27 |
Zoals je ziet levert dit soms een positief getal op en soms een negatief getal. Om te zorgen dat alle getallen positief worden nemen we voor elke regel het kwadraat. Daarna tellen we alle residuen bij elkaar op. Dit levert de zogeheten Som van Residuen op (SSR, Sum of Squard Residuals in het Engels). Hetzelfde doen we voor de afwijkingen, waarmee we de Som van Kwadratische afwijkingen krijgen (SST, Sum of Squared Totals). De R2 is dan vervolgens uit te rekenen door de som:
![]()
In ons voorbeeld levert dat de volgende R2 op:
![]()
Als we goed naar de formule kijken zien we dat de R2 dus eigenlijk kijkt hoe veel beter of slechter onze voorspelling is dan wanneer we gewoon elke keer de gemiddelde waarde zouden voorspellen. Er zijn 3 soorten uitkomsten mogelijk:
- R2 > 0: de voorspelling is nauwkeuriger dan wanneer we altijd het gemiddelde zouden teruggeven. Hoe dichter bij 1 de R2 hoe beter de voorspelling.
- De R2 = 0: de voorspelling is net zo goed als wanneer we altijd het gemiddelde zouden teruggeven.
- De R2 < 0: de voorspelling is slechter dan wanneer we altijd het gemiddelde zouden teruggeven.
Het kan voorkomen dat je op een trainingsdataset een hoge R2 krijgt, maar zodra je het op een nieuwe dataset toepast ineens een lage R2 krijgt. Dit kan verklaard worden door het fenomeen “overfitting”. Bij overfitting heeft het model verbanden gelegd, tussen de input variabelen en de output, die er in werkelijkheid niet zijn. Een voorbeeld van overfitting is bijvoorbeeld wanneer een student voor een examen oefent door alleen naar de oude examens van vorige jaren te kijken. Als er dan ineens een nieuwe opdrachtsvormen in een nieuw examen zitten weet de student het antwoord niet. Overfitting kan je voorkomen door een grotere trainingsset te gebruiken of het aantal input variabelen te beperken.
Een hoge R2 kan een indicatie zijn van een goed voorspelmodel, maar er is wel een beperking. Alle afwijkingen worden als even belangrijk gezien, hoewel we het misschien vervelend vinden als we er ver naast zitten . Stel bijvoorbeeld we moeten verse bloemen inkopen doen voor 5 verschillende verkoopdagen. We hebben dan liever een voorspelmodel dat er 5 keer een klein beetje naast zit dan een model dat 4 keer de juiste waarde voorspelt, maar de 5e keer met een grote marge naast zit.
Een meetwaarde die daar beter rekening mee houdt is de Root Mean Square Error (RMSE). Om de RMSE te berekenen kijken we weer naar de SSR, maar dit keer delen we die som door het aantal waarnemingen en vervolgens nemen de wortel:
![]()
Een hoge RMSE betekent dat het voorspel model er gemiddeld verder naast zit dan bij een lage RMSE. Bij het kiezen van het juiste model is het verstandig om zowel naar de R2 als de RMSE te kijken en te kiezen voor een balans die past bij jouw probleem.
Modellen vergelijken
Nu we weten hoe de verschillende modellen worden gescoord kunnen we een goede afweging maken bij het selecteren van het juiste model. Om je daarbij te helpen genereert AutoML automatisch een dashboard waarin de verschillende meetwaarden per mogelijk model worden getoond. Je vindt deze onder het tabblad “Compare”.
De Compare app bestaat uit 2 sheets. De eerste sheet heet “Model Comparison” en heeft 2 visualisaties. Links staat een staafgrafiek genaamd “Model performance”, met per mogelijk model de score voor een bijpassende meetwaarde. Rechts staat een staat een scatterplot, waar je verschillende meetwaarden tegen elkaar kunt afzetten. Middels de selectiebalken onderin kan je zelf de meetwaarde selecteren die het beste past bij jouw vraagstuk.
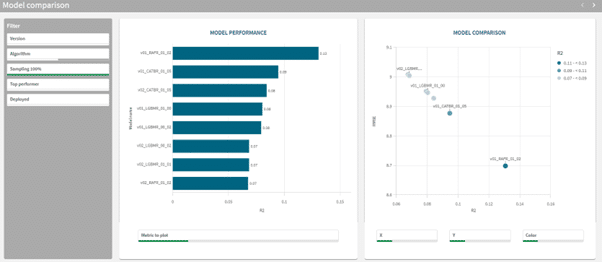
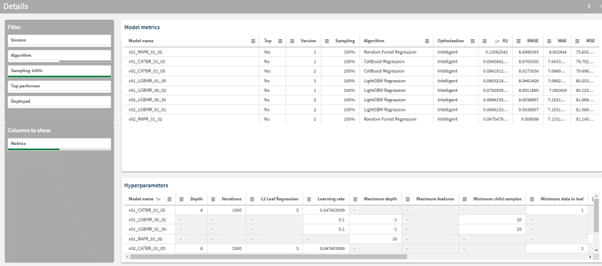
De tweede sheet, genaamd “Details” bevat ook 2 visualisaties. De bovenste tabel geeft voor elke optie alle verschillende meetwaarden weer die van toepassing zijn op dat model. Door op de kolom headers te klikken kan je de tabel op die meetwaarde selecteren.
De onderste tabel geeft de “Hyperparameters” weer. Dit zijn de instellingen die AutoML heeft gebruikt voor dat specifieke algoritme. Deze hyperparameters zijn vooral nuttig als je diepe inhoudelijke kennis hebt van de verschillende gebruikte algoritmen.
Wanneer je na analyse het juiste model hebt gevonden voor jouw probleem druk je op de knop “Deploy” om het model actief te maken. Hoe dit verder in zijn werk gaat leer je in het volgende blog in deze serie!
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant






