Aan de slag met AutoML: feature engineering

De toekomst voorspellen, wie wil dat nou niet? Met Qlik AutoML kun je eenvoudig voorspelmodellen creëren op basis van jouw data. Zoals de naam van de functionaliteit verraadt, automatiseert Qlik AutoML een groot deel van dit proces voor je. Desondanks heb je als gebruiker nog steeds wel een hoop invloed op de effectiviteit van het voorspelmodel. In de blogserie: aan de slag met AutoML leggen we uit wat je kunt doen om jouw voorspelmodellen met AutoML nog beter te maken en hoe je de resultaten kunt integreren in je bestaande Qlik dashboards.
Wat is Feature Engineering
In dit eerste deel van het blog kijken we naar “feature engineering”. Feature engineering is het proces waarbij je domeinkennis gebruikt om jouw dataset zo aan te passen dat het zo effectief mogelijk kan worden gebruikt voor het voorspellen.
Gelukkig zijn er al een aantal stappen in dit proces die AutoML voor je kan doen. Dat merk je zodra je een dataset inlaadt in jouw AutoML experiment. Zie bijvoorbeeld de afbeelding hieronder:
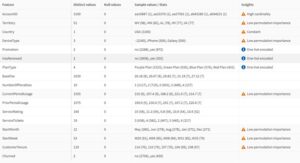
In de kolom ‘Insights’ zie je dat Qlik AutoML “One-hot encoding” toepast op onze kolommen met minder dan 14 keuzewaarden. Bij kolommen met 14 of meer keuzewaarden gebruikt Qlik “Impact encoding”. Deze coderingstechnieken zijn voor veel machine learning modellen een vereiste om goed met dit soort informatie om te kunnen gaan.
Een andere verwerkingsstap die Qlik automatisch voor je uitvoert is “Null imputation”. Dit betekent dat Qlik velden waar (minder dan 50% van de) waarden ontbreken zelf aanvult, bijvoorbeeld door het gemiddelde van de overige waarden te nemen en die op deze lege plekken in te vullen. Qlik kiest zelf welke methode wordt gebruikt om deze imputatie uit te voeren.
Tot slot zal Qlik ook automatisch waarden schalen en normaliseren. Wat betekent dat hij voor numerieke waarden het gemiddelde en de standaardafwijking berekent en vervolgens de kolom normaliseert op basis van het aantal standaardafwijkingen van het gemiddelde.
Zelf je dataset aanpassen
Hoewel Qlik een hoop werk voor je doet, zijn er ook stappen die je zelf kunt nemen om jouw data nog beter voor te bereiden voor het machine learning model. Het is voor Qlik niet mogelijk om deze optimalisaties zelf door te voeren omdat ze context en kennis van de echte wereld vragen . We behandelen 3 veel voorkomende technieken:
1. Categoriseren
Stel je voor: we werken in de bloemensector en willen een voorspelmodel maken voor het aantal rozen dat we verkopen. In onze historische data hebben we een aantal eigenschappen, waaronder per datum het aantal verkochte rozen van een bepaalde kleur en formaat.
We kunnen deze dataset direct in AutoML gooien, maar we weten dat rozen op specifieke dagen meer verkocht worden, zoals rond Moederdag en Valentijnsdag. Deze kennis kunnen we in onze dataset verwerken. De meest eenvoudige manier is om een vlaggetje te maken voor bijzondere dagen:
| Datum | IsFeestdag |
| 12-02-2025 | 0 |
| 13-02-2025 | 0 |
| 14-02-2025 | 1 |
| 15-02-2025 | 0 |
Op deze manier weet ons model welke dagen feestdag zijn en kan hij dit meenemen in het model. Denken we er nog iets langer over na, dan weten we dat in de dagen voor en na een dergelijke feestdag vaak ook nog extra rozen worden verkocht, want niet iedereen geeft de rozen op de dag zelf. We kunnen dan bijvoorbeeld 2 kolommen introduceren:
| Datum | DagenTotFeestdag | DagenSindsFeestdag |
| 12-02-2025 | 2 | 42 |
| 13-02-2025 | 1 | 43 |
| 14-02-2025 | 0 | 0 |
| 15-02-2025 | 86 | 1 |
2. Discreet maken en groeperen
Sommige velden in je dataset hebben heel veel verschillende waarden, denk bijvoorbeeld aan een kolom met leeftijden, daar komen in theorie allerlei waarden tussen de 0 en 100 voor. De exacte leeftijd is echter vaak niet relevant voor de waarde die je wil voorspellen. Het maakt niet zo veel verschil of iemand 32 of 35 jaar oud is. Het maakt misschien wel een verschil of iemand 16 of 85 is. Om dit op te lossen kun je de kolom leeftijd transformeren in leeftijdsgroepen:
| Leeftijd | Leeftijdsgroep |
| 0-12 | Kind |
| 12-17 | Puber |
| 18-25 | Jongvolwassene |
| 25-65 | Volwassene |
| 65+ | Senior |
Uiteraard kunnen de groepen anders zijn afhankelijk van het soort data waar je mee werkt, dat is precies waar je jouw expertise toevoegt.
3. Splitsen van eigenschappen
Soms bevatten kolommen in jouw dataset stiekem meerdere gegevens. Een klassiek voorbeeld daarvan is de datum en tijd. Een kolom met datum en tijd gecombineerd heeft vaak weinig voorspellende waarde omdat er zoveel verschillende waarden zijn dat ze nagenoeg uniek zijn per regel.
Dit kan je oplossen door het veld op te splitsen in aparte datum- en tijdvelden. Vanuit het datumveld zou je het seizoen of kwartaal kunnen berekenen en het tijdveld zou je nog verder kunnen versimpelen tot het uur en de minuten. Uiteraard kun je hier ook de combinatie maken met het groeperen zoals hierboven beschreven, door bijvoorbeeld de tijd op te splitsen in ochtend, middag, avond en nacht.
Conclusie
Zoals je ziet zijn er veel verschillende manieren waarop je jouw data kunt manipuleren voordat je het in AutoML laadt. Vaak is dit een iteratief proces: je past de data aan, laat AutoML een model trainen en kijkt vervolgens of de nieuwe features belangrijk zijn voor het model. Hoe je ziet welke features belangrijk zijn in jouw model en hoe je kan beoordelen of jouw model succesvol is lees je in ons volgende blog in deze serie, dus stay tuned!
Blijf op de hoogte
Wil jij geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant







