Hoe vind je “code smells” in TimeXtender?

Het is volop lente en dat is een goed moment voor een voorjaarsschoonmaak van je TimeXtender implementaties. In deze serie blogs zoomt Senior TimeXtender Consultant Ruairidh Smith in op typische zaken die je kan verbeteren, zeker voor langlopende implementaties of implementaties die door meerdere ontwikkelaars worden opgezet. Dit zijn zaken die meestal als “details” worden gezien die minder belangrijk zijn dan het opleveren van nieuwe data. In deze tweede editie gaan we iets minder de technische diepte in en kijken we naar functionaliteit binnen TimeXtender die je helpt om “code smells” te vinden. Code smell is een term uit software-engineering die refereert aan stukken code die verbetering kunnen gebruiken via refactoring. In data warehousing is het equivalent het zoeken naar aanwijzingen die wijzen in de richting van efficiency- of begrijpbaarheids-verbeteringen.
Maak gebruik van het gereedschap dat je al hebt: Data Profile, Reports, Logging
Terwijl je je implementatie bouwt handelt TimeXtender de datakwaliteit automatisch voor je af. De meeste mensen zullen dit meemaken via Primary Key checks: als je databron dubbele records bevat voor de sleutel die je hebt gedefinieerd zal TimeXtender (onder standaardinstellingen) niet toestaan dat die duplicaten doorkomen in je valid tabel. Key collisions worden apart gezet in error tables waarin je kan zien welke records niet doorkomen om welke redenen. In het normale geval stel je je sleutels in en denk je er niet meer over na, maar het is altijd goed om periodiek te checken of je aannames nog steeds kloppen. Als je bijvoorbeeld nieuwe data toevoegt uit een andere bron in een bestaande dimensie kan het zijn dat er duplicaten ontstaan: je komt ze niet tegen in je valid table, maar ze worden wel weggeschreven naar de error tables.
Binnen TimeXtender kun je via het Reports menu alle Errors en Warnings direct inzien. Het is dus goed om nadat je in de weer bent geweest met sleutels of Field Validations even een check te doen om te zien of er errors voorkomen. Als je er nog nooit in hebt gekeken is het zowiezo goed om er een blik op te werpen: het kan zijn dat er een hoop data weggevangen wordt!
Als voorbeeld zien we in de afbeelding hieronder records die niet voldoen aan een Field Validation die alleen Product-records doorlaat als het gefinaliseerde producten betreft. Als ik bijvoorbeeld een nieuwe bron voor product data toe zou voegen en zou vergeten om dat veld correct te initialiseren zouden geen van die records doorkomen. De error en warning reports tonen de inhoud van de _L en _M tabellen en laten je de verschillende soorten errors filteren.
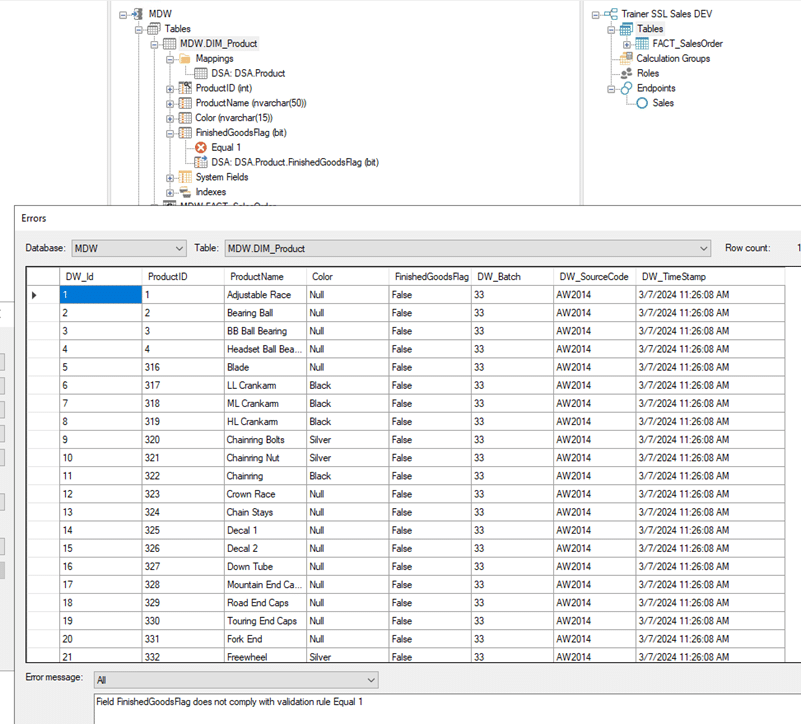
TimeXtender Error Report met Field Validation errors
“Bekende” errors die niet actief worden opgelost
In de praktijk kom ik nog wel eens tegen dat er “bekende” errors zijn die niet actief worden opgelost. Hoewel dit prima kan werken is het een impliciete manier om met een probleem om te gaan dat makkelijk over het hoofd wordt gezien of wordt vergeten bij een overdracht. Omdat errors en warnings records genereren in de _L en _M tabellen kan dit ook een performance bottleneck opleveren als er vele foutieve records zijn. Bijvoorbeeld als het toevoegen van een nieuwe mapping op een tabel meer dubbelingen oplevert dan verwacht.
Eén aspect om in de gaten te houden wanneer je de PK-kwaliteitscontroles met opzet gebruikt, is dat het eerste record met een PK zal doorgaan naar de valid tabel, maar de volgende records niet. Zonder aangepast script kun je de laadvolgorde niet beïnvloeden en daarom kun je de verkeerde records naar je geldige tabel laden als je je daar niet van bewust bent.
Een voorbeeld van zo’n situatie is een incrementeel laadscenario waarbij je delta’s meerdere rijen kunnen bevatten voor dezelfde primaire- of bedrijfssleutel. In dergelijke situaties wil je misschien de laatste rij in de set behouden in plaats van de eerste rij omdat het laatste record het meest recent is. Aangezien er geen directe controle is over de rijvolgorde in de cleansing stap tussen raw- en valid tabel, zul je een andere manier moeten vinden om de juiste records te bepalen. Je zou kunnen overwegen om de rijvolgorde die naar de raw tabel gaat te beïnvloeden en hopen dat je DWH-engine niet besluit om records in een andere volgorde te leveren. Dit zal werken totdat het dat niet doet; veranderingen in de SQL-engine of misschien migreren naar een ander type engine zoals Synapse of Snowflake kunnen bijwerkingen hebben op dit vlak. Een manier die consistentie garandeert, is het gebruik van een Aggregatietabel om de winnaar te kiezen of het gebruik van custom SQL-script.
Data Profile
Met de nieuwe release van TimeXtender heb je de beschikking over een handige nieuwe feature: de Data Profile. Dit geeft je basale statistiek op de inhoud van iedere kolom in je tabellen. Iedere keer dat je je data execute wordt de statistiek bijgewerkt. Eén van de meest voor de hand liggende toepassingen is het checken op NULLs zonder de Query Tool in een Preview te hoeven gebruiken. Als je bijvoorbeeld je surrogaatsleutel opzet aanpast is het verstandig even een blik te werpen op de velden die je daarvoor gaat gebruiken.
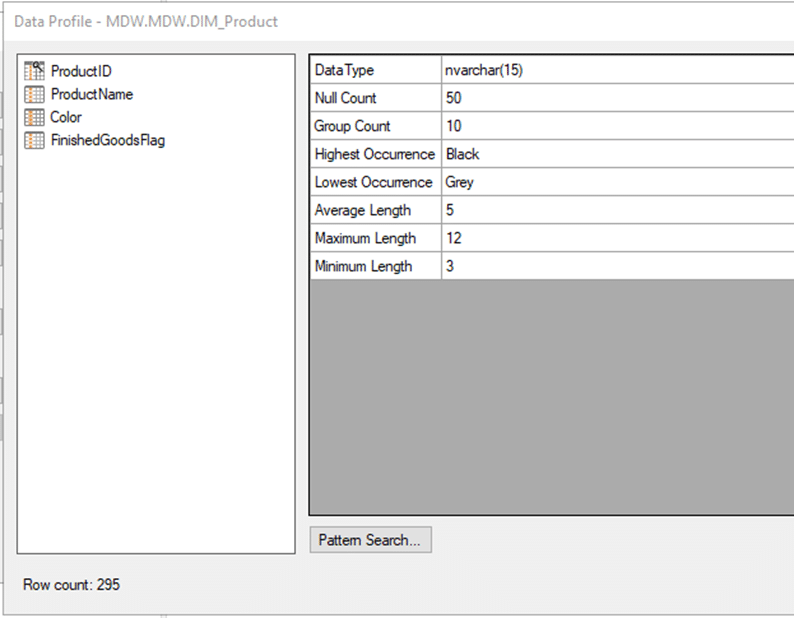
TimeXtender Data Profile
Een andere handige optie is het snel kunnen zien wat de minimum- en maximumwaarden voor een datumveld zijn: misschien verwacht je daar geen datums in de toekomst aan te treffen maar zijn ze er wel omdat er iets in een business proces is veranderd met problemen in je logica als gevolg.
Als laatste voorbeeld is er de mogelijkheid om de distributie van waarden in een categorisch veld te bevragen zoals te zien in onderstaande afbeelding.
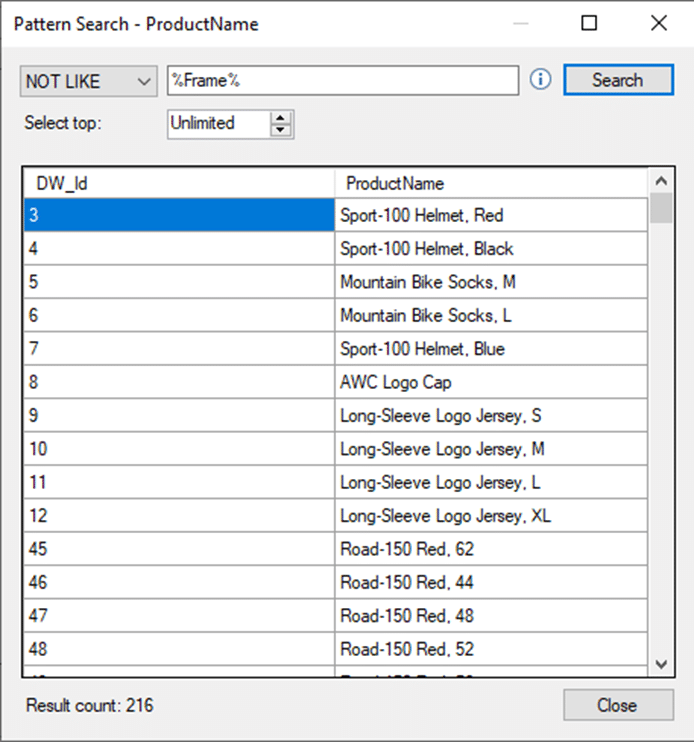
Data Profile Pattern Search
Logging
Wanneer je een performance analyse uitvoert is de Execution Log Overview erg handig: je krijgt inzicht in historische runtime, aantallen records en aantallen errors. Zo kun je snel begrijpen waarom je tabel er nu langer over doet om te herladen of laat je inzien dat je vergeten bent om Truncate Valid table before cleanse weer aan te zetten nadat je Incremental Load hebt uitgezet op een tabel.
In de afbeelding hieronder zien we dat het aantal records in de valid tabel van de DIM_Product tabel in MDW is verdubbeld in de laatste run ten opzichte van de runs daarvoor. Dit gebeurt omdat ik in de tabel settings Simple Mode heb uitgezet omdat ik een Field Validation wilde implementeren. Als je Simple Mode uitzet moet je Truncate valid table before data cleansing weer aanzetten omdat die voor Simple Mode uitstaat. Zonder de logging te checken kan dit problem sluimeren totdat het een probleem in een rapportage oplevert.
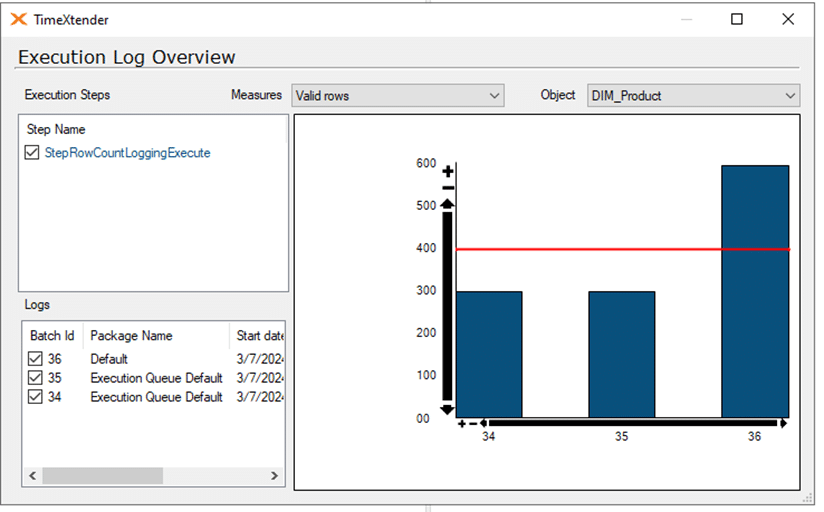
Execution Log Overview – Row count
Eén van de simpelste dingen om te checken is hoeveel tijd ieder onderdeel van het herladen van een tabel in beslag neemt. Hieruit kun je tot de conclusie komen dat een kleine tabel sneller laadt als de tabel volledig wordt verladen in plaats van incrementeel.
Concluderend: TimeXtender bevat een hoop mogelijkheden om te controleren dat je implementatie zich naar verwachting gedraagt zonder dat er sluimerende problemen op de loer liggen. Als je de potentiële issues onder controle hebt maakt dat het een stuk makkelijker om generieke tools als de SQL Server Query Store te gebruiken om te focussen op je database performance.
Technische voetnoot: SQL Server levert meestal records in laadvolgorde aan als er geen expliciete ORDER BY is aangegeven in een query. Deze volgorde is echter niet gegarandeerd als er geen ORDER BY wordt toegepast. Als je bijvoorbeeld data laadt naar SQL Server uit een CSV bestand zal SQL Server tot nu toe de records in file-volgorde inlezen (bij een single-threaded laadproces). Dit is een effect van hoe SQL Server is geïmplementeerd maar niet onderdeel van een in beton gegoten afspraak. Het werkt zo totdat het niet meer zo werkt. Gezien we nu bewegen naar een tijdperk waar je niet altijd meer in detail in controle bent over de onderliggende infrastructuur, wordt het steeds belangrijker om de nadruk te leggen op wat er moet gebeuren en daarmee impliciete aannames op het gebied van de hoe zoveel mogelijk te vermijden. Als je bijvoorbeeld van SQL Server op een Virtuele Machine naar Snowflake migreert zul je kunnen merken dat er op detail andere gedragingen voorkomen.
Op de hoogte blijven?
Benieuwd naar de rest van deze reeks blogs? Schrijf je dan in voor onze nieuwsbrief, zo ben jij maandelijks up-to-date van al onze nieuwe blogs. Je kunt je inschrijven via de button hieronder.

Geschreven door Ruairidh Smith,
Senior consultant bij E-mergo







